golang 切片
切片结构
1 | type slice struct { |
1 | a = make([]int, 0) |
切片组成元素:
- 指针:指向底层数组
- 长度:切片中元素的长度,不能大于容量
- 容量:指针所指向的底层数组的总容量
初始化方式
- 使用make
1
2slice := make([]int, 5) // 初始化长度和容量都为 5 的切片
slice := make([]int, 5, 10) // 初始化长度为 5, 容量为 10 的切片
使用 make 关键字创建切片时,很多工作都需要运行时的参与;调用方必须在 make 函数中传入一个切片的大小以及可选的容量,[cmd/compile/internal/gc.typecheck1](https://github.com/golang/go/blob/b7d097a4cf6b8a9125e4770b54d33826fa803023/src/cmd/compile/internal/gc/typecheck.go#L327-L2126) 会对参数进行校验:
1 | func typecheck1(n *Node, top int) (res *Node) { |
上述函数不仅会检查 len 是否传入,还会保证传入的容量 cap 一定大于或者等于 len,除了校验参数之外,当前函数会将 OMAKE 节点转换成 OMAKESLICE,随后的中间代码生成阶段在 [cmd/compile/internal/gc.walkexpr](https://github.com/golang/go/blob/4d5bb9c60905b162da8b767a8a133f6b4edcaa65/src/cmd/compile/internal/gc/walk.go#L439-L1532) 函数中的 [OMAKESLICE](https://github.com/golang/go/blob/4d5bb9c60905b162da8b767a8a133f6b4edcaa65/src/cmd/compile/internal/gc/walk.go#L1315) 分支依据两个重要条件对这里的 OMAKESLICE 进行转换:
- 切片的大小和容量是否足够小;
- 切片是否发生了逃逸,最终在堆上初始化
虽然大多的错误都可以在编译期间被检查出来,但是在创建切片的过程中如果发生了以下错误就会直接导致程序触发运行时错误并崩溃:
- 内存空间的大小发生了溢出;
- 申请的内存大于最大可分配的内存;
- 传入的长度小于 0 或者长度大于容量;
[runtime.makeslice](https://draveness.me/golang/tree/runtime.makeslice) 在最后调用的 [runtime.mallocgc](https://draveness.me/golang/tree/runtime.mallocgc) 是用于申请内存的函数,这个函数的实现比较复杂,如果遇到了比较小的对象会直接初始化在 Go 语言调度器里面的 P 结构中,而大于 32KB 的对象会在堆上初始化
为啥是32kb
- 界限的选择是基于一些性能和内存管理的考虑。
- 小于等于32KB的对象被认为是比较小的,可以在 P 结构中进行初始化。这样做有以下几个优点:
- 减少对堆的访问:将对象初始化在 P 结构中可以避免频繁地访问堆,减少内存的分配和释放操作,提高程序的性能。
- 提高局部性:将对象与对应的 P 结构关联起来,可以提高数据的局部性,减少内存访问的延迟,进一步提升性能。
- 大于32KB的对象被认为是较大的对象,其内存需求比较高。将这些对象直接初始化在堆上有以下几个优点:
- 堆的管理更加灵活:堆提供了更加灵活的内存管理机制,可以根据需要动态分配和释放内存,适应各种大小的对象。
- 避免过度占用 P 结构:将大对象初始化在堆上可以避免过度占用 P 结构的内存空间,保持 P 结构的高效利用。
使用简短定义
1 | slice := []int{1, 2, 3} |
- 使用数组来初始化切片
1 | arr := [5]int{1, 2, 3, 4, 5} |
- 使用切片来初始化切片
1
2sliceA := []int{1, 2, 3, 4, 5}
sliceB := sliceA[0:3] // 左闭右开区间,sliceB 最终为 [1,2,3]
扩容例子
- 注意点
- 多个切片共享一个底层数组的情况,对底层数组的修改,将影响上层多个切片的值
- 多个切片共享一个底层数组的情况,对底层数组的修改,原有的切片发生了扩容 底层数组被重新创建 ,和原来的切片已经没有关系了
- 扩容的slice还和类型(其实是类型占的字节)有关
1 | e := []int32{1,2,3} |
1 | package main |
以上代码预期输出如下:
1 | before modify underlying array: |
使用 copy 方法可以避免共享同一个底层数组
1 | package main |
以上代码预期输出如下:
1 | before modifying underlying array: |
扩容分析
通过 append 关键字被转换的控制流了解了在切片容量足够时如何向切片中追加元素,但是当切片的容量不足时就会调用 [runtime.growslice](https://github.com/golang/go/blob/440f7d64048cd94cba669e16fe92137ce6b84073/src/runtime/slice.go#L76-L191) 函数为切片扩容,扩容就是为切片分配一块新的内存空间并将原切片的元素全部拷贝过去,我们分几部分分析该方法:
1 | func growslice(et *_type, old slice, cap int) slice { |
后半部分还对 newcap 作了一个内存对齐,这个和内存分配策略相关。进行内存对齐之后,新 slice 的容量是要 大于等于 老 slice 容量的 2倍或者1.25倍。
1 | package main |
运行结果是:
1 | len=5, cap=6 (如果按照1.25倍的说法就是5,8,但实际上是错误的) |
这个函数的参数依次是 元素的类型,老的 slice,新 slice 最小求的容量。
例子中 s 原来只有 2 个元素,len 和 cap 都为 2,append 了三个元素后,长度变为 5,容量最小要变成 5,即调用 growslice 函数时,传入的第三个参数应该为 5。即 cap=5。而一方面,doublecap 是原 slice容量的 2 倍,等于 4。满足第一个 if 条件,所以 newcap 变成了 5。 接着调用了 roundupsize 函数,传入 40。(代码中ptrSize是指一个指针的大小,在64位机上是8)
再看内存对齐,搬出 roundupsize 函数的代码:
1 | func roundupsize(size uintptr) uintptr { |
最终返回
1 | class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]] |
这是 Go 源码中有关内存分配的两个 slice。class_to_size通过 spanClass获取 span划分的 object大小。而 size_to_class8 表示通过 size 获取它的 spanClass。
1 | var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31} |
传进去的 size 等于 40。所以 (size+smallSizeDiv-1)/smallSizeDiv = 5;获取 size_to_class8 数组中索引为 5 的元素为 4;获取 class_to_size 中索引为 4 的元素为 48。最终,新的 slice 的容量为 6:
1 | newcap = int(capmem / ptrSize) // 6 |
- 预估容量(预估”元素个数”)
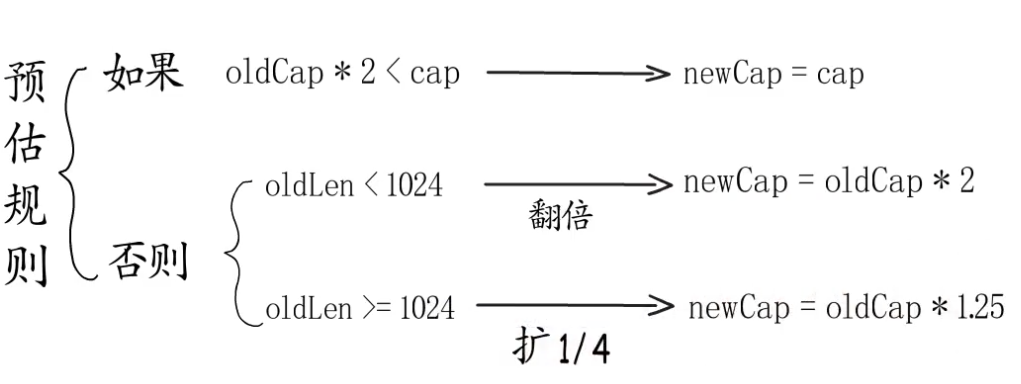
注意:(官方代码在2020-09-25 换成了 if old.cap < 1024{} )
- 如果新申请容量(cap)大于旧容量(old.cap)的两倍,则最终容量(newcap)是新申请的容量(cap);
- 如果旧切片的长度小于 1024,则最终容量是旧容量的 2 倍,即“newcap=doublecap”; (注意1.18后时256)
- 如果旧切片的长度大于或等于 1024,则最终容量从旧容量开始循环增加原来的 1/4,直到最终容量大于或等于新申请的容量为止;(注意1.18后时256,>=512)
- 如果最终容量计算值溢出,即超过了 int 的最大范围,则最终容量就是新申请容量。
- 分配内存 = 预估容量 * 元素类型大小
申请分配内存是语言自身实现的内存管理模块向操作系统申请(合适的内存规格:8,16,32,48,64,80,96,112……字节,64位下每个元素占16字节。32位下占8字节,其中查看类型占多少字节用unsafe.Sizeof()来判断,但是又如何得知当前平台是在处于多少为的系统。可以用以下来判断(比如int在64为下占8个字节,string在64为下占10个字节)
1 | 32 << (^uint(0) >> 63) |
^uint(0)在32位系统上返回的是0XFFFFFFFF, 也就是2^32, 在64位系统上返回的是0xFFFFFFFFFFFFFFFF, 也就是2^64
申请分配内存会匹配到最接近的规格
确认了最新容量后,则进行内存对齐。通过对元素的大小(et.size)的判断,对了内存对齐。通过数组class_to_size拿到对齐的值。
- newCap = 申请分配内存 / 元素类型大小
在1.22版本后切片的扩容机制变更为
- 初始化变量:函数接受两个参数,newLen 表示切片的新长度,oldCap 表示切片的旧容量。开始时将 newcap 初始化为 oldCap。
- 判断是否需要直接扩容至新长度:首先计算 doublecap,即旧容量的两倍。如果新长度大于 doublecap,则直接返回新长度,因为此时直接扩容到新长度即可。
- 阈值判断:定义了一个阈值常量 threshold,其值为 256。如果旧容量小于该阈值,那么新容量直接设置为 doublecap。
- 循环计算新容量:对于大于等于阈值的旧容量,采用一种新的扩容策略,即每次增加 newcap 的 1.25 倍,直到 newcap 大于等于 newLen。
- 溢出检查:通过将 newcap 强制转换为 uint 类型进行溢出检查。如果 newcap 溢出,则直接返回新长度。
- 返回新容量:最后返回新容量,如果新容量小于等于 0,则返回新长度,以防溢出。
这个机制在处理切片扩容时,尤其是针对大容量的切片,可以更加有效地管理内存,避免频繁的内存分配和拷贝操作,从而提高性能。
拷贝切片
当我们使用 copy(a, b) 的形式对切片进行拷贝时,编译期间的 [cmd/compile/internal/gc.copyany](https://github.com/golang/go/blob/bf4990522263503a1219372cd8f1ee9422b51324/src/cmd/compile/internal/gc/walk.go#L2980-L3040) 函数也会分两种情况进行处理,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
之后,向 Go 内存管理器申请内存,将老 slice 中的数据复制过去,并且将 append 的元素添加到新的底层数组中。
最后,向 growslice 函数调用者返回一个新的 slice,这个 slice 的长度并没有变化,而容量却增大了。
1 | n := len(a) |
例子
1 | arr := [10]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} |
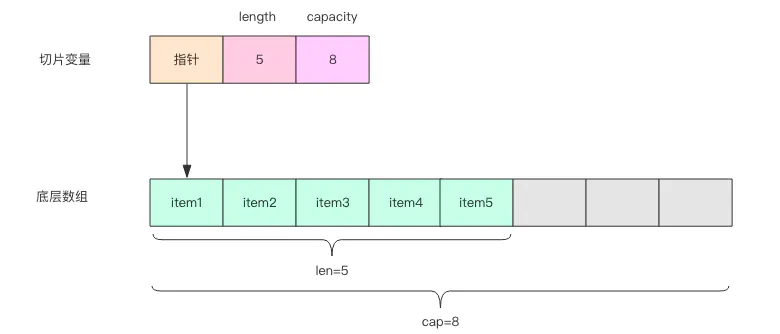
一个切片的容量可以被看作是透过这个窗口最多可以看到的底层数组中元素的个数。注意,切片代表的窗口是无法向左扩展的。(前面提到的)
使用技巧
1 | a = a[:len(a)-1] // 删除尾部1个元素 |
假设切片里存放的是指针对象,那么下面删除末尾的元素后,被删除的元素依然被切片底层数组引用,从而导致被自动垃圾回收器回收(这要依赖回收器的实现方式):
保险的方式是先将需要自动内存回收的元素设置为nil,保证自动回收器可以发现需要回收的对象,然后再进行切片的删除操作:
1 | var a []*int{ ... } |
同理
截掉切片[i,j)之间的元素:
1 | a = append(a[:i], a[j:]...) |
上面的Cut如果元素是指针的话,会存在内存泄露,所以我们要对删除的元素设置nil,等待GC。
1 | copy(a[i:], a[j:]) |
Delete(GC)
1 | copy(a[i:], a[i+1:]) |
切片使用不当对内存的泄露
- 应该将原切片拷到一个新的切片操作,比如使用切片的前5个slice
1
2
3
4
5func getMessageType(msg []byte) []byte {
msgType := make([]byte, 5)
copy(msgType, msg)
return msgType
}
分组切片
1 | func chunk(actions []int, batchSize int) [][]int { |
同时数组可以作为 map 的 k(键),而切片不行
它的大小和类型在编译时就已经确定了。
append函数的常见操作
- 删除位于索引 i 的元素:a = append(a[:i], a[i+1:]…)
- 切除切片 a 中从索引 i 至 j 位置的元素:a = append(a[:i], a[j:]…)
- 为切片 a 扩展 j 个元素长度:a = append(a, make([]T, j)…)
- 索引 i 的位置插入切片 b 的所有元素:a = append(a[:i], append(b, a[i:]…)…)
并发安全
slice 是非协程安全的数据类型,如果创建多个 goroutine 对 slice 进行并发读写,会造成丢失。看一段代码
1 | package main |
多次执行,每次得到的结果都不一样,总之一定不会是想要的 10000 个。想要解决这个问题,按照协程安全的编程思想来考虑问题
可以考虑使用 channel 本身的特性(阻塞)来实现安全的并发读写。
1 | func main() { |
slice 坑
bar 执行了 append 函数之后,最终也修改了 foo 的最后一个元素,这是一个在实践中非常常见的陷阱。
1 | foo := []int{0, 0, 0, 42, 100} |
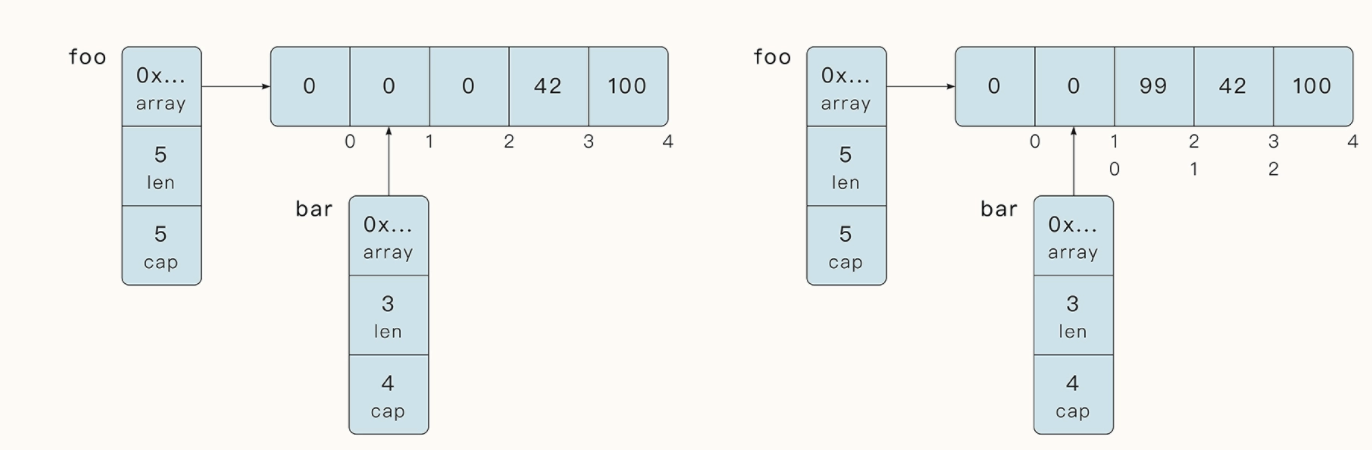
bar 的 cap 容量会到原始切片的末尾,所以当前 bar 的 cap 长度为 4。
如果要解决这样的问题,其实可以在截取时指定容量:
1 | foo := []int{0,0,0,42,100} |
foo[1:4:4] 这里,第三个参数 4 代表 cap 的位置一直到下标 4,但是不包括下标 4。 所以当前 bar 的 Cap 变为了 3,和它的长度相同。当 bar 进行 append 操作时,将发生扩容,它会指向与 foo 不同的底层数据空间。由于bar的容量足够,它将继续使用foo的底层数数组,所以foo也被修改成了[0, 0, 0, 42, 99]。
切片中的三种特殊状态
切片的三种特殊状态 —— 「零切片」、「空切片」和「nil 切片」。
空切片和 nil 切片的区别在于,空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。
不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。
通过 unsafe.Pointer 来转换 Go 语言的任意变量类型。
1 | var s1 []int |
其中输出为 [0 0 0] 的 s1 和 s4 变量就是「 nil 切片」,s2 和 s3 变量就是「空切片」。824634199592 这个值是一个特殊的内存地址,所有类型的「空切片」都共享这一个内存地址。
空切片指向的 zerobase 内存地址是一个神奇的地址
「 nil 切片」和 「空切片」在使用上有什么区别么?
最好办法是不要创建「 空切片」,统一使用「 nil 切片」,同时要避免将切片和 nil 进行比较来执行某些逻辑。这是官方的标准建议。(正确选择 var res []int )
1 | package main |
「空切片」和「 nil 切片」有时候会隐藏在结构体中,这时候它们的区别就被太多的人忽略了,看个例子
1 | type Something struct { |
「空切片」和「 nil 切片」还有一个极为不同的地方在于 JSON 序列化
1 | type Something struct { |
注意,对于切片的判断最好使用len()==0
参考

